
one step
[파이썬] 태그 수집, 중복 태그 수 세어 딕셔너리형으로 반환하기 본문
반응형
명언 태그 수집
배운 내용을 활용해 명언 사이트를 크롤링해보도록 하겠습니다. http://quotes.toscrape.com/
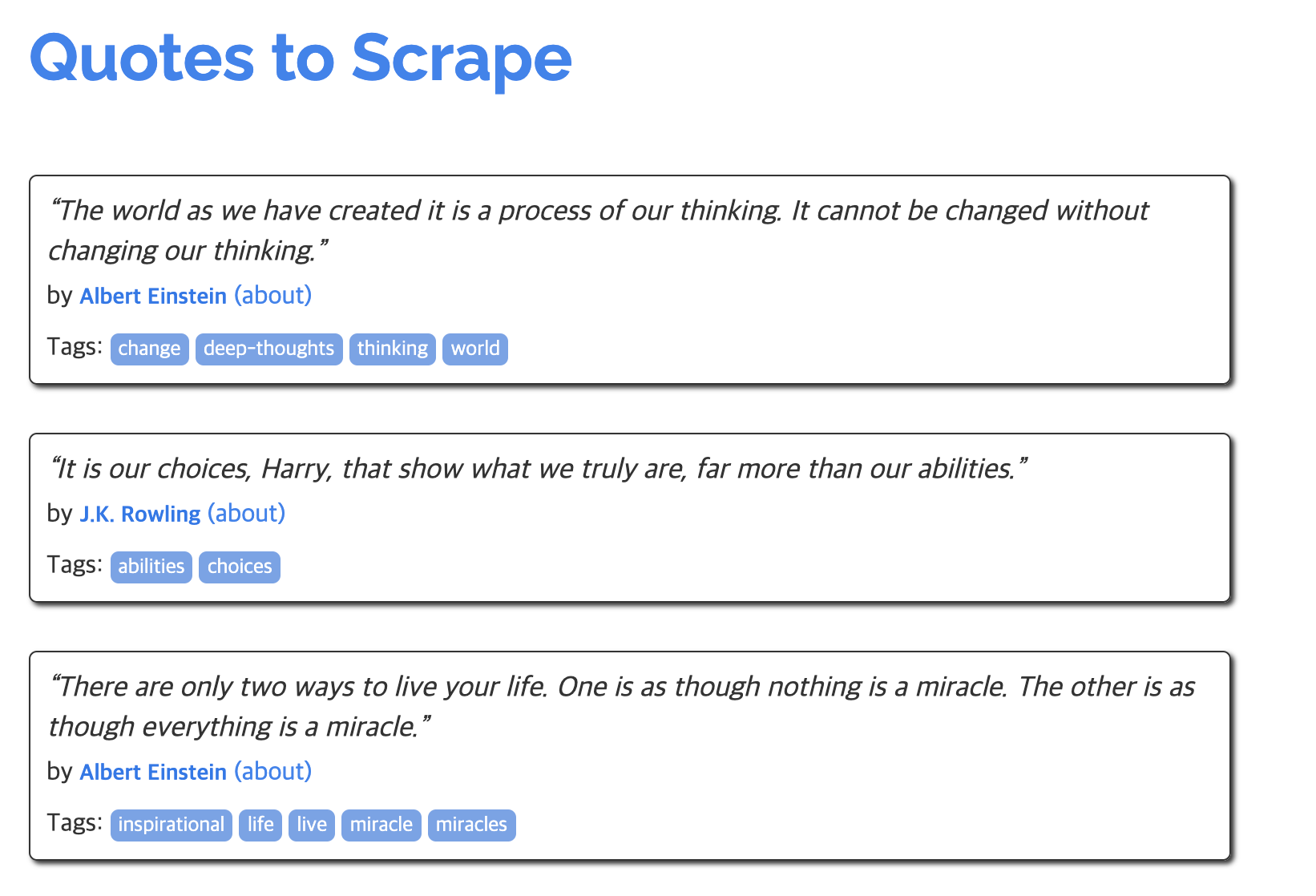
해당 명언 페이지의 명언들의 태그(예: change deep-thoughts thinking world)들의 빈도수를 조사하고자 합니다.
지시사항
함수 crawl_contents가 올바르게 구현되어야 합니다.
crawl_contents 함수
- 매개변수: webdriver와 스크래핑 해야 하는 웹 페이지의 url
- 반환값: 첫 페이지에 존재하는 명언 총 10개에서 태그(문자열)를 key로 갖고, 태그의 빈도수(int)를 value로 갖는 딕셔너리
- 예를 들어 inspirational 태그의 빈도가 10이고 life 태그의 빈도가 5라면 딕셔너리 내에서 {'inspirational': 10, 'life': 5} 와 같은 형태로 저장되어있어야 합니다.
main 함수
- main 함수에서 crawl_contents 함수를 호출하여 구현 결과를 테스트해볼 수 있습니다.
채점 기준
crawl_contents 함수의 반환값이 올바른 값이라면 정답으로 처리됩니다.
Tips!
- 페이지 우측의 Top Ten Tags의 내용은 포함하지 않습니다.
- webdriver 는 main 함수에서 이미 실행된 것에 유의하여 crawl_contents 함수를 작성해주세요.
# 초기 코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.expected_conditions import presence_of_element_located
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.firefox.options import Options as FirefoxOptions
def crawl_contents(driver, url):
# 명언들의 태그의 빈도를 담고 있는 딕셔너리를 반환하세요.
tags = {}
return tags
def main():
# 브라우저 web driver 설정(Firefox)
options = FirefoxOptions()
with webdriver.Firefox(options=options) as driver:
# 데이터를 가져올 사이트의 URL
url = "http://quotes.toscrape.com/"
print(crawl_contents(driver, url))
if __name__ == "__main__":
main()
# 완성 코드
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.expected_conditions import presence_of_element_located
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.firefox.options import Options as FirefoxOptions
def crawl_contents(driver, url):
driver.get(url)
# 명언들의 태그의 빈도를 담고 있는 딕셔너리를 반환하세요.
tags = {}
tag_list = []
div_list = driver.find_elements_by_class_name('tags')
for div in div_list:
keywords = div.find_element_by_class_name('keywords')
tag1 = keywords.get_attribute('content')
tag2 = tag1.split(',')
for tag in tag2:
tag_list.append(tag)
for item in tag_list:
tags[item] = tag_list.count(item)
print(tags)
return tags
def main():
# 브라우저 web driver 설정(Firefox)
options = FirefoxOptions()
with webdriver.Firefox(options=options) as driver:
# 데이터를 가져올 사이트의 URL
url = "http://quotes.toscrape.com/"
print(crawl_contents(driver, url))
if __name__ == "__main__":
main()반응형
'이것저것 코드 > 파이썬' 카테고리의 다른 글
| [Python] 문장 분석 전처리하고 word cloud 만들기 (0) | 2022.10.02 |
|---|---|
| [파이썬] 텍스트와 텍스트의 반복 수 조합해 딕셔너리 만들기 (0) | 2022.09.16 |
| [파이썬] webdrive 메서드와 url 매개변수가 다른 함수에 있을 때 (0) | 2022.09.16 |
| [파이썬] 비동기 화면 크롤링하기 (wait 사용하기) (0) | 2022.09.16 |
| [파이썬] 페이지네이션 있는 페이지에서 값 추출 및 딕셔너리 만들기 (1) | 2022.09.16 |
'이것저것 코드/파이썬' Related Articles
more


